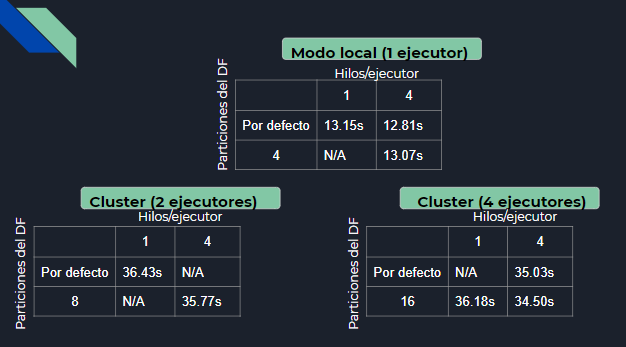
Rendimiento
Si ejecutamos Spark en modo local, este número será siempre 1. Sin embargo, si estamos lanzándolo en un cluster, podremos tener tantos ejecutores como nodos vayamos añadiendo. Eso sí, en este caso será necesario quitar el siguiente fragmento de código en la inicializaciónd de Spark:
Número de ejecutores
Si ejecutamos Spark en modo local, este número será siempre 1. Sin embargo, si estamos lanzándolo en un cluster, podremos tener tantos ejecutores como nodos vayamos añadiendo. Eso sí, en este caso será necesario quitar el siguiente fragmento de código en la inicializaciónd de Spark:
setMaster('local[*]')Número de hilos/ejecutor
Una vez más distinguimos entre modo local y cluster. En modo local, especificamos a Spark que queremos que use cree tantos hilos como cores haya disponibles. De ahí la línea:
spark-submit --num-executors --executor-cores script En modo cluster, le especificamos que use los cores directamente al lanzar el script
Número de tareas
Podemos especificar cuántas tareas distintas creará Spark por debajo para hacer el shuffle. Estas tareas coinciden, en nuestro caso,
con el número de particiones que se harán del dataframe en cuestión. Usando una heurística bastante fiable, establecemos el nº de tareas (o particiones) al
producto de los ejecutores * hilos que tiene cada uno. De esta forma conseguimos tiempos óptimos, y significa que cada core disponible estaría encargándose de una partición del dataframe